Unlocking Data Precision: How the Variance Formula Transforms Uncertainty in Statistical Analysis
Unlocking Data Precision: How the Variance Formula Transforms Uncertainty in Statistical Analysis
In statistical analysis, uncertainty is inevitable—but unmanaged uncertainty sabotages insights. At the core of transforming raw data into actionable truth lies a deceptively simple mathematical expression: the variance formula. Far more than a computational tool, variance quantifies dispersion, revealing how data points deviate from their mean and exposing the reliability of statistical estimates.
It is the cornerstone of precision in fields ranging from financial forecasting to medical research, enabling analysts to distinguish signal from noise with clarity and confidence. Understanding variance begins with a fundamental insight: averaging alone distorts truth. When data spreads widely around a central value, the mean rises misleadingly.
Variance captures this divergence, converting observed differences into a standardized metric that reflects true data instability. As statistician David Freedman once noted, “Variance is not just a number—it’s a narrative of dispersion, a proxy for trust in your dataset’s story.” This precision enables researchers to validate models, assess risk, and make decisions grounded in evidence rather than guesswork.
At its mathematical core, the variance formula computes the average squared deviation from the mean.
For a population, it is expressed as σ² = Σ(X − μ)² / N, where X denotes each data point, μ is the population mean, N is the sample size, and Σ denotes summation. This formula translates abstract uncertainty into quantifiable dispersion: larger values signal high variability, while smaller values indicate stability and consistency. When applied across datasets, variance transforms immersive noise into actionable insight, empowering analysts to distinguish outliers from representative patterns.
Consider clinical trials where drug efficacy hinges on consistent patient response.
A low variance in treatment outcomes suggests reliability, signaling confidence in the intervention. Conversely, high variance might reveal biological heterogeneity or flawed measurement—critical feedback for refining protocols. In finance, variance quantifies market risk: a portfolio’s volatility, derived from variance, dictates risk tolerance.
Portfolio managers use it alongside mean returns to optimize allocations—balancing growth potential with acceptable uncertainty.
Variance also fuels advanced analytical techniques. It underpins standard deviation—the square root of variance—making dispersion directly interpretable in original units. More sophisticated methods, such as analysis of variance (ANOVA), extend the principle to compare multiple groups, identifying significant differences that static summaries miss.
This hierarchical application of variance-derived measures elevates statistical analysis from descriptive reporting to predictive power, guiding hypothesis testing and inference.
Modern statisticians emphasize that precision begins with rigor in variance calculation. Incomplete or biased data distort variance, undermining conclusions. Techniques like stratified sampling, robust estimators, and residual analysis ensure variance reflects genuine dispersion, not artifacts of flawed sampling.
According to methodologist Jason Wand to Forbes, “Variance is the quiet architect of statistical trust—get it right, and every insight holds weight; get it wrong, and conclusions crumble.”
In real-world applications, variance’s impact stretches beyond theory. In manufacturing, quality control systems monitor product dimensions via variance thresholds—metrics that trigger corrective action before defects cascade. In climate science, variance across temperature measurements across decades reveals subtle shifts otherwise obscured by seasonal noise.
Social scientists rely on variance to assess income inequality, policy effectiveness, and educational outcomes, turning individual anecdotes into measurable trends.
While variance is indispensable, its interpretation demands nuance. A low variance does not imply truth—only stability—and high variance does not invalidate findings—it signals sources of variation. Effective analysts contextualize variance within domain knowledge: Why does this dataset vary widely?
What external factors drive dispersion? Only with such insight does variance become a true driver of precision, not just a number.
As statistical tools grow more sophisticated, the variance formula endures as a foundational pillar. Its simplicity belies profound power: transforming scattered data points into coherent narratives, quantifying doubt with clarity, and elevating analysis from speculation to certainty.
In an era overwhelmed by information, mastery of variance empowers analysts to cut through uncertainty—turning raw data into decisive insight, one squared deviation at a time.
The variance formula is not merely a technical tool but a transformative force in statistical practice. By precisely measuring dispersion, it turns ambiguity into actionable knowledge, enabling researchers and decision-makers alike to navigate complexity with confidence. In unlocking data precision, variance remains the silent architect of statistical truth.

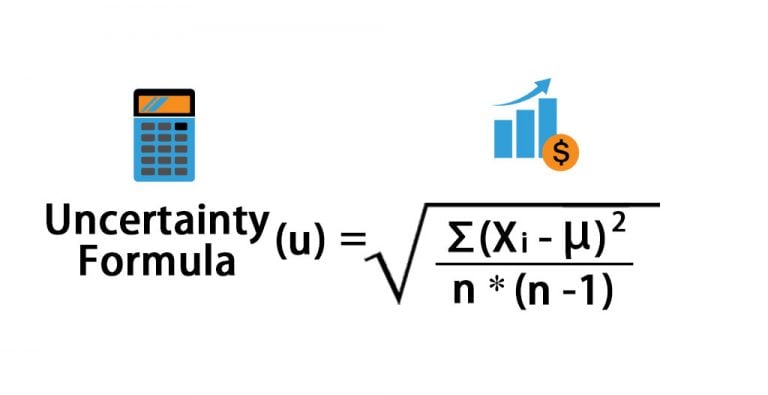

Related Post

What Time Is It Virginia? Thewiry Clock That Defines a Virginia Moment

<strong>Cepl Ozellink: The Engine of Urban Connectivity Reshaping Modern Mobility</strong>
.jpg?format=original)
Is Hampton Inn A Marriott Hotel Unpacking The Brand Brook From The Brand Stack?

How Rich Is Paula Deen Now? Analyzing the Network Star’s Financial Trajectory



